Uvod Link to heading
Danas je skoro svako čuo za Large Language Modele (LLM) i više miliona ljudi ih je koristilo do sada. Međutim, nije tako veliki broj ljudi koji razume kako oni zaista rade. - To je nešto što želim promeniti ovom serijom postova.
“Bilo koja izuzetno napredna tehnologija se ne može razlikovati od magije.”
Arthur C. Clarke“Ko to menja vrednost u registru unutar Motorole 68K, da nisu možda neki gremlini unutra koji premeštaju te vrednosti?”
Prof. Krca
Spoiler alert: Ukoliko želite da verujete u magiju ili gremline, savetujem da preskočite ovu seriju postova o LLM
Ukoliko ste čuli nešto o ovoj temi, verovatno ste čuli da su LLM trenirani da “predvide sledeću reč” i da oni zahtevaju velike količine teksta kako bi uopšte mogli to da rade. No, tu se objašnjenje uglavnom završava, sam detaljni postupak kako dolazi do predviđanja sledeće reči se uglavnom tretira kao velika misterija (neka magija).
Jedan od razloga je drugačiji način razvoja samih LLM sistema. Standardni software uglavnom je napravljen od strane ljudi (programera), koji daju računarima eksplicitne instrukcije (step-by-step). Nasuprot tome LLM-ovi su napravljeni uz pomoć neuronskih mreža koje su učene(trenirane) na milijardama reči.
Zbog toga, jako je teško razumeti šta se zaista dešava unutar LLM-a. Cilj ove serije postova je da što široj publici približi znanja koje su eksperti do sada već istražili o LLM-ovima. Trudiću se da objašnjenja imaju što manje tehničkog žargona, kao i matematike.
Kako to računar razume moj upit? Link to heading
Verujem da je većina vas već koristila neku vrstu LLM-a ( PartyRock.aws , Claude ili ChatGPT) I prilikom istog ste morali da napravite upit (prompt). Ljudi predstavljaju reči uz pomoć niza slova, na primeru K-R-A-J za reč “kraj”. Nažalost, računar nije u stanju da “razume” vaš upit kao što to mogu ljudi, već se koristi dugi niz brojeva, još poznat kao word vector. Na primeru, ovako se moze reč kralj (king) predstaviti kao vektor:
[0.01852, 0.03002, -0.03966, -0.01276, 0.038243, 0.06484, -0.00994, -0.10205, 0.10219, -0.05766, 0.03118, 0.07707, -0.00436, 0.01516, -0.10468, -0.13384, 0.00101, -0.04979, -0.01186, 0.03934, 0.01152, ... , -0.01053]
Ceo vektor ima 300 brojeva. Ukoliko želite da vidite ceo niz, kliknite ovde i onda kliknite na “show raw vector.”
Verovatno se pitate zašto je potrebno preko 300 brojeva kako bi predstavili reč kralj? Možemo objasniti na prostom primeru igre potapanja brodova gde koordinatni sistem ima 10 redova i 10 kolona. Svaki brod možemo predstaviti kordinatama u sklopu vektora na primeru:
- Brod 1 je na [3,4]
- Brod 2 je na [9,2]
- Brod 3 je na [5,5]
Ovo je korisno kako bi imali predstavu o prostornim vezama. Možemo zaključiti da je Brod 1 blizu Broda 3 kako je red Broda 3 udaljen za 2 polja dok je kolona udaljena za 1 polje. Isto tako možemo videti da je najveća razdaljina između Broda 2 i Broda 1.
LLM-ovi koriste sličan pristup: Svaki word vector predstavlja tačku u imaginarnom polju reči, i reči koje imaju slično značenje će biti bliže jedna drugoj. Tehnički, LLM-ovi koriste fragmente reči zvane tokene. Na primeru, reči koje su najbliže reči kralj u samom polju reči uključuju kraljicu, kraljeve, prinčeve i princeze. Glavna prednost reprezentacije reči pomoću vektora realnih brojeva ( nasuprot slova ) je da brojevi omogućavaju više operacija od samih slova.
Teško je predstaviti reči u dve dimenzije. Iz tog razloga LLM koristi polja reči sa stotinu, ako ne i hiljada dimenzija. Ljudi nisu u stanju da zamisle polja sa toliko dimenzija, ali za računare to ne predstavlja nikakav problem, te im omogućava da dođu do rezultata.
Već par decenija naučnici koriste word vektore u svojim eksperimentima, koncept je dobio zalet kada je Google objavio svoj word2vec projekat 2013. Google je analizirao milione dokumenata sa Google News servisa kako bi shvatio koje reči se pojavljuju u sličnim rečenicama. I tako su neuronske mreže originalno učene da predvide koje reči se pojavljuju sa drugim rečima, kao krajnji rezultat smestile slične reči (kao kralj i kraljica) blizu jedne drugoj u vektorskom prostoru.
Word vektori imaju još jednu zanimljivu osobinu, uz pomoć vektorske aritmetike možemo da shvatimo značenje. Na primeru, ukoliko bi uzeli vektor za reč “najveći” i oduzeli vektor za “veliki” i onda dodali vektor “mali”. Reč koja bi bila najbliža tom vektoru bi bila “najmanji”.
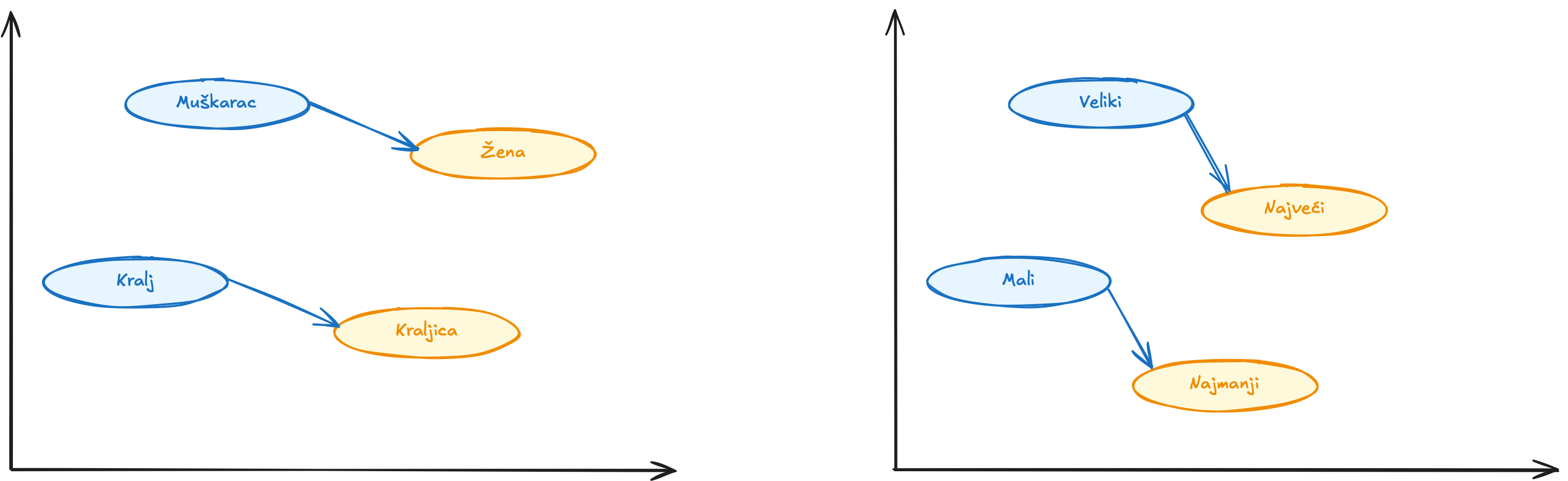
Možete koristiti vektorsku aritmetiku kako bi zaključili analogiju. U ovom slučaju veliki je ka najveći kao što je mali ka najmanji. Googlovi word vektori su obuhvatili i dosta drugih veza:
- Pariz je prema Francuskoj isto što je Berlin ka Nemačkoj ( glavni gradovi )
- Nemoguće je prema mogućem isto što je neetički ka etičkom ( suprotnosti )
- Mačka je prema mačkama isto što je dolar ka dolarima ( množina )
- Muškarac je prema ženi isto što je kralj prema kraljici ( polovi )
Kako su vektori napravljeni od rečenica koje su ljudi napravili, oni takođe reflektuju dosta pristrastnosti koje su prisutne u ljudskom jeziku. Na primer, kod nekih modela vektora, “doktor minus muškarac plus žena” daće “sestra (medicinska)”. Rešavanje ovakvih pristrasnosti je aktivno područje u istraživanju.
I pored toga, word vektori su važni deo fundamentalnih blokova LLM-a, jer oni sadrže sve bitne informacije o vezama između reči. Ukoliko jezički model nauči nešto o mačkama (npr. ponekad idu kod veterinara), isto će najverovatnije važiti za psa i druge kućne ljubimce. Ukoliko model nauči o vezi između Pariza i Francuske (npr. da imaju isti jezik), dobra je šansa da će isto važiti za Berlin i Nemačku, kao i za Rim i Italiju.
Značenje reči zavisi od konteksta Link to heading
Prosti modeli vektora reči nisu u stanju da prikupe važne činjenice o prirodnom jeziku: Reči uglavnom imaju više značenja.
Na primeru, reč “kosa” može se odnositi na alat za košenje trave, na nešto što nije ravno ili na dlake kose na glavi. Drugi primer je reč “zub”, koji može da se odnosi na zub u vilici ili zub na testeri ili zub na zupčaniku itd.
Kada reč ima dva različita značenja, kao u slučaju reči “kosa”, lingvisti to zovu homonimija. Kada reč ima jako slično značenje, kao u slučaju reči “zub”, lingvisti to zovu polisemija.
LLM-ovi mogu predstaviti istu reč sa različitim vektorima u zavisnosti od konteksta gde se ta reč nalazi. Tu je vektor za “zub” u vilici i drugačiji vektor za “zub” na testeri. Kao što možete očekivati, LLM-ovi koriste slične vektore za polisemine nego u slučaju homonima.
Tradicionalni software je dizajniran da radi sa podacima koji su jednoznačni. Ukoliko zadamo računaru da nam izračuna “2+3”, nema zabune oko toga šta to znači. U slučaju prirodnog jezika to nije slučaj i imamo dosta dvosmislenosti koji idu dosta dublje od honimonije i polisemije:
- U rečenici “Klijent je pitao mehaničara da popravi njegov auto”, da li se “njegov” odnosi na klijenta ili mehaničara?
- U rečenici “Profesor je zatražio od učenika da urade svoj domaći”, da li se “svoj” odnosi na profesora ili učenike?
- U rečenici “Vreme leti jako brzo”, da li je “leti” glagol (leteti) ili je priloška odredba (za leto)
Ljudi mogu rešiti ove probleme uz pomoć konteksta, ne postoji neki lakši način ili neka određena pravila koja bi nam u ovome pomogla. Ovo zahteva razumevanje činjenica o samom svetu. Morate da znate da mehaničari uglavnom popravljaju automobile klijenata, da studenti uglavnom rade svoj domaći.
Word vektori omogućavaju fleksibilni način jezičnim modelima da predstave precizno značenje reči u određenom kontekstu.
Zaključak Link to heading
Da vidimo kako to računar razume vaš upit u par koraka:
- Računar transformiše reči (ili tokene) u vektore
- Na osnovu konteksta bira odgovarajuće vektore
- Niz svih tih vektora omogućava računaru da zadrži smisao i vezu reči vašeg upita
- Uz pomoć tog niza računar će izgenerisati odgovor (predviđanje)
Kako LLM radi iza kulisa, očekujte u narednom postu, gde ćemo se više pozabaviti kako se generiše predviđanje, odnosno odgovor koji nam LLM-ovi vraćaju.