Uvod Link to heading
U prethodnom postu Kako to računar razume moj upit smo objasnili kako od reči dolazimo do nizova vektora koje predstavljaju naše reči zadržavajući veze i kontekst teksta. Sada idemo korak dalje da vidimo kako dolazi do predviđanja od strane LLM-a da li su to neki gremlini ili neka magija?
Kako dolazi do predviđanja na osnovu niza vektora? Link to heading
Llama 3, najnovija generacija Open Source LLM-a od strane Mete je dostupna od Aprila 2024, i ima preko 30 transformacijskih slojeva. Svaki sloj procesira sekvencu vektora kao ulaz, gde za svaku reč u našem upitu je zadužen jedan vektor. Tokom procesiranja svaki sloj će dodati informacije koje će pojasniti značenje te reči i omogućiti bolje predviđanje sledeće reči.
Hajde da pogledamo na prostom primeru.
``
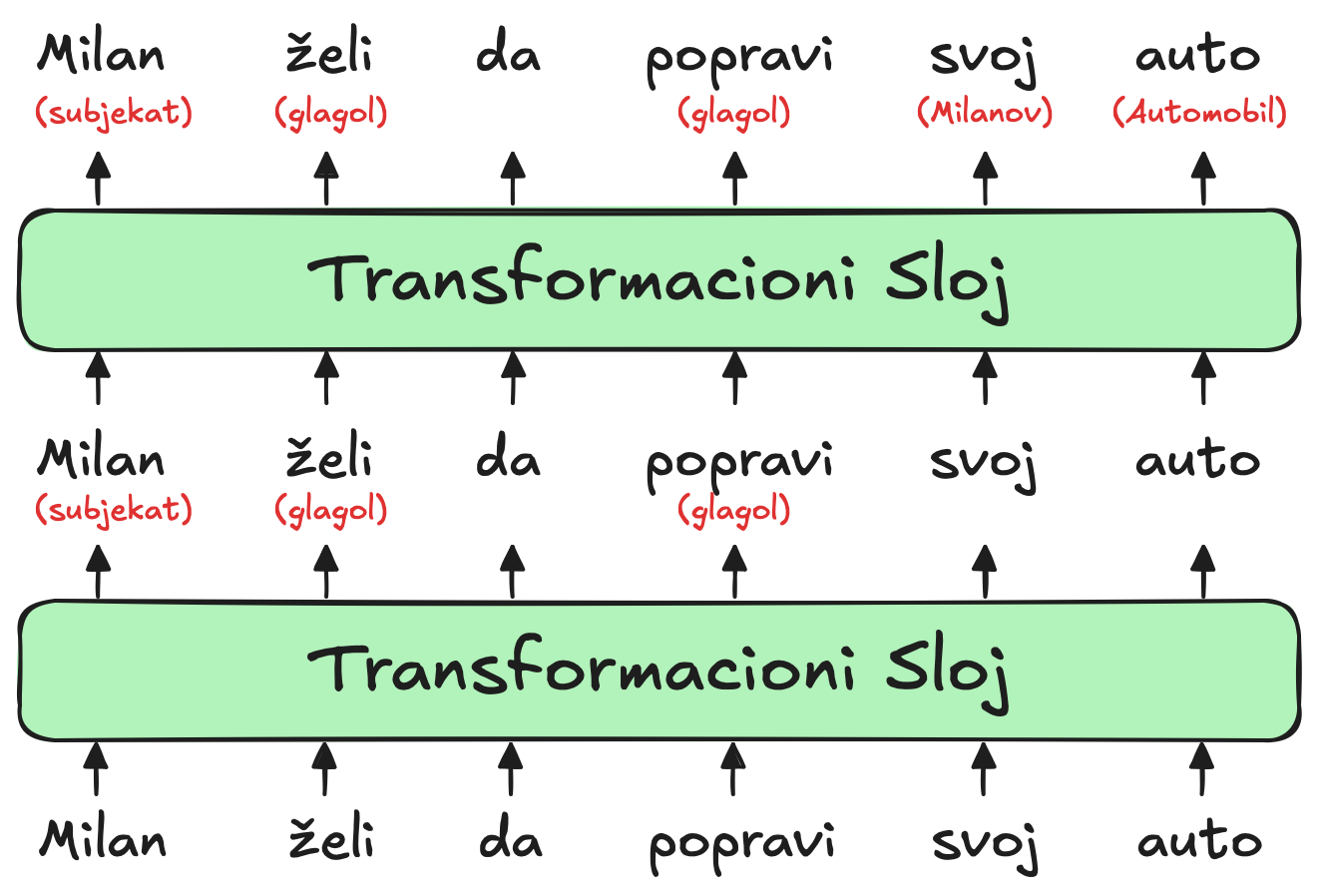
Svaki sloj LLM-a je transformer, neuronska arhitektura koju je prvo objavio Google u svom poznatom radu iz 2017. godine.
Ulaz za sam model je prikazan na dnu dijagrama, u pitanju je nezavršena rečenica “Milan želi da popravi svoj auto”. Ove reči, predstavljene uz pomoć word vektora se šalju ka prvom transformeru.
Transformer zatim identifikuje reči “želi” i “popravi” kao glagole dok reč “Milan” detektuje kao subjekat. Dodatni kontekst prikazujemo crvenim slovima ispod samih reči u dijagramu, dok sam model taj kontekst čuva u izmenjenim word vektorom na način koji je nama ljudima težak za razumevanje. Ovi novi vektori, takođe poznati kao sakrivena stanja, se onda prosleđuju sledećem transformeru.
Drugi transformer zatim dodaje nove kontekste:
- Pojašnjava da je reč “auto” u ovom slučaju Automobil
- I da se reč “svoj” odnosi na Milana kao prisvojna zamenica.
Takođe kao i kod prvog transformera rezultat će biti novi niz skrivenih vektora koji reflektuju sve što je model identifikovao do tog trenutka.
Dijagram predstavlja fiktivnu arhitekturu modela i služi čisto kako bi mi mogli bolje da razumemo šta se dešava iza kulisa. Kod pravih LLM-ova imamo malo više nego 2 sloja transformera, kod LLame 3 8b imamo 32 sloja transformera, odnosno Llama 3 405b ima 126 sloja transformera.
Istraživanja su pokazala da prvih nekoliko slojeva transformera imaju fokus na razumevanje sintakse rečenice i rešavanje nejasnoća kao što možemo videti iznad na dijagramu. Kasniji slojevi, koje nismo uključili u naš dijagram zbog prostora, mogu razumeti na visokom nivou cele pasuse kao celine.
Na primeru, kako LLM procesira kratku priču, može se primetiti da vodi računa o raznim informacijama o likovima u priči: pol i starost, odnos ka drugim karakterima, trenutna i prethodna lokacija, ličnost i ciljevi, i tako dalje.
Naučnici ne razumeju tačno kako LLM vodi računa o ovim informacijama, ali logički gledano, model to verovatno čini prilikom izmene vektora u skrivenim stanjima kako prolaze iz jednog sloja ka drugom sloju. Tome doprinosi i činjenica da su kod modernih LLM-a vektori veoma veliki.
Na primeru, Llama 3 koristi word(token) vektore sa dimenzijom od 4096 - što znači, da je svaka reč predstavljena sa listom od 4096 brojeva. To je barem 12 puta veće nego word2vec koji smo koristili u prethodnom postu. Sve ove dodatne dimenzije možemo zamisliti kao polja koje LLM koristi da zapiše informacije o kontekstu svake reči. I tako informacije koje je model zapisao u ranijim slojevima biće dostupne za čitanje i izmenu kasnijim slojevima transformera. Na taj način model može postepeno da dodaje informacije na osnovu kojih na kraju ima dobar kontekst pasusa kao celine.
Zamislimo da smo promenili naš dijagram iznad da sadrži svih 32 slojeva modela za kratku priču od više stotina reči. Dvadeseti sloj bi možda sadržao vektor za “Milan” sa kontekst komentarom “(glavni lik u priči, muško, ujak Dragan, iz Vranja, trenutno u Sarajevu, pokušava da opravi svoj auto na putu za Italiju.)”. Sve ove činjenice bi mogle da budu nekako zabeležene unutar liste od 4096 brojeva za zadatu reč “Milan”. Ili možda neke od ovih informacija su zabeležene u vekotrima za Auto, Put, Italiju ili neke druge reči u samoj priči.
Cilj završnog 32 sloja mreže je da nam da skriveno stanje za krajnju reč koja uključuje sve potrebne informacije za predviđanje sledeće reči.
Molim za malo vaše pažnje! Link to heading
Hajde da vidimo šta se to dešava unutar samog sloja transformera. Transformer ima proces od dva koraka za samu promenu skrivenog stanja svake reči:
- U koraku pažnje (attention), reči “dele” svoj kontekst i ostale informacije sa drugim rečima na osnovu reči u neposrednoj blizini
- U koraku unapred (feed-forward), svaka reč “razmišlja” o informacijama koje su prikupljene u prethodnim koracima pažnje i prave predviđanje sledeće reči.
Naravno u pitanju je cela mreža ne same reči koje izvršavaju ove korake. Svakako transformeri rade sa vektorima reči koja je osnovna jedinica za analizu. Ovaj pristup omogućava LLM-ovima da iskoriste paralelno procesiranje na modernim grafičkim čipovima (GPU).
Mehanizam pažnje možemo zamisliti kao uparivanje reči. Svaka reč pravi kontrolnu listu (zvanu query-vektor) opisujući karakteristike reči koje traži. Svaka reč takođe pravi kontrolnu listu (zvanu key-vektor) gde opisuje svoje karakteristike. Mreža upoređuje svaki key-vektor sa svakim query-vektorom (koristeći skalarni proizvod) kako bi našla reči koje najviše odgovaraju. Kada mreža pronađe par onda informacije od reči koja je proizvela key-vektor prenese informaciju ka reči koja je proizvela query-vektor.
Na prethodnom primeru smo pokazali da transformer može zaključiti da reč “svoj” u reči “Milan želi da popravi svoj auto” se odnosi na Milana. Evo kako bi to moglo da izgleda iza kulisa. Query-vektor za “svoj” bi mogao da glasi, “Ja tražim imenicu koja opisuje mušku osobu”. Dok bi key-vektor za reč “Milan” mogao da glasi, “Ja sam imenica koja opisuje mušku osobu”. Mreža bi mogla da detektuje da su ova dva vektora slična i da prebaci informacije o vektoru “Milan” u vektor “svoj”.
Svaki sloj transformera zadužen za pažnju ima nekoliko glava pažnje, što znači da se ova razmena informacija dešava nekoliko puta paralelno unutar svakog sloja. Svaka glava se fokusira na različit zadatak.
- Jedna glava može upoređivati imenice i zamenice
- Druga glava može raditi na rešavanju homonima kao što je u slučaju reči “kosa”
- Treća glava može povezivati fraze od dve ili više reči tipa “Milan Milovanović”
Glave pažnje uglavnom rade u sekvenci, tako što rezultati jedne glave postaju ulaz za procesiranje sledeće u narednom sloju.
Najveća verzija Llama 3 405B (milijardi) ima 126 slojeva sa 128 glava pažnje, što znači da Llama 3 izvrši 16.126 operacije za predviđanje svake reči.
Korak unapred, nikako unazad! Link to heading
Kada glave pažnje razmene informacije između word vektora, tu dolazi feed-forward mreža koja “razmišlja” o svakom word vektoru i pokušava da predvidi narednu reč. U ovom koraku ne dolazi do razmene informacija između vektora. Sloj za feed-forward analizira svaku reč u izolaciji. Ovaj sloj ima pristup svim informacijama koje su prethodno razmenile glave pažnje. Evo kako može da izgleda struktura jednong feed-forward sloja:
``
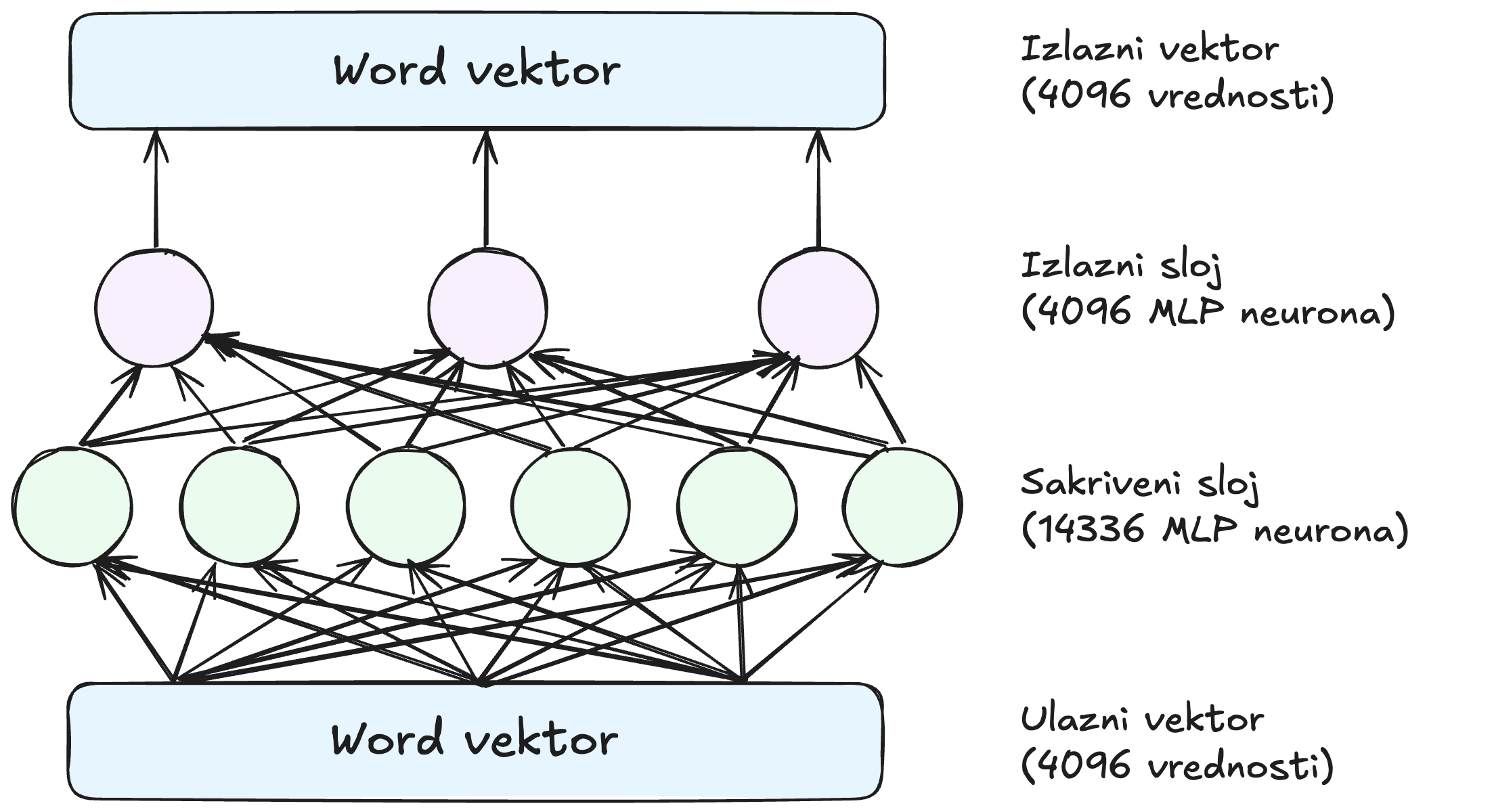
Krugovi zelene i roze boje predstavljaju neurone, matematičke funkcije koje računaju sumu ulaza. Suma se onda prenosi dalje na aktivacionu funkciju.
Ono što čini feed-forward mrežu snažnom je velika količina veza. Mi smo mrežu radi preglednosti prikazali sa 3 neurona u izlaznom sloju. Svakako izlazna mreža Llame 3 je dosta veća 4096 neurona u izlaznom sloju(koji odgovara veličini našeg word vektora) i 14.336 neurona u svakom skrivenom sloju.
Tako da kog Llame 3 mi imamo 14.366 neurona u skrivenom sloju, sa 4096 ulaza (i zbog toga 4096 odlučujućih parametara) za svaki neuron. I imamo 4096 izlaznih neurona sa 14366 ulaznih vrednosti (samim tim 14366 parametara) za svaki neuron. To znači da svaki feed-forward sloj ima 4096*14366 + 14366*4096 = 117 miliona parametara. To onda treba pomnožiti sa 32 sloja koliko ukupno imamo gde dolazimo do ukupno 3,7 milijardi parametara. U slučaju Llama3 8B to je polovina svih parametara.
U radu iz 2020, istraživači sa Tel Aviv Univerziteta su pronašli da feed-forward slojevi rade tako što pronalaze obrasce: Svaki neuron u skrivenom sloju traži određeni obrazac u tekstu. Evo nekoliko obrazaca koje neuroni traže u GPT-2 verziji sa 16 sloja:
- Neuron u prvom sloju traži sekvence reči koje se završavaju sa “substitutes”.
- Neuron u šestom sloju traži sekvence koje su vezane za vojsku i završavaju sa “base” ili “basess” (baza i baze)
- Neuron u trinaestom sloju traži sekvence koje se završavaju se vremenskim opsegom kao npr “između 4 popodne i 8” ili “od Petka 20:00”
Kao što možete da vidite, obraci su sve apstraktniji u kasnijim slojevima. Rani slojevi više traže specifične reči, gde kasniji slojevi traže fraze koje spadaju u šire semantičke kategorije kao što su vremenski opsezi.
Ovo je interesantno jer, kao što smo pomenuli ranije, feed-forward slojevi istražuju reč po reč. Tako da kod klasifikacije sekvence “izmežu 4 popodne i 8 ujutru” koja je vezana za vremenski opseg, sloj ima pristup samo vektoru reči “ujutru”, nema pristup rečima “između” ili “i”. Feed-forward može zaključiti da “ujutru” je deo opisa vremenskog opsega jer su glave pažnje prethodno prebacile kontekst informacije unutar vektora “ujutru”.
Kada neuron naiđe na jedan od ovakvih obrasca, on dodaje informacije word vektoru. Iako nije jednostavno interpretirati ovu informaciju, u dosta slučaja možemo zamisliti kao potencijalnu predviđanje sledeće reči.
Feed-forward mreže razmišljaju uz pomoć vektorske matematike Link to heading
Nedavno istraživanje sa Brown Univerziteta otkrilo je elegantan primer kako feed-forward slojevi pomažu u predviđanju sledeće reči. Ranije smo pričali o Guglovom word2vec istraživanju koje je pokazalo da je moguće koristiti vektorsku aritmetiku za analogno zaključivanje. Na primer, Berlin - Nemačka + Francuska = Pariz.
Istraživači sa Brauna su otkrili da feed-forward slojevi ponekad koriste upravo ovaj metod za predviđanje sledeće reči. Na primer, proučavali su kako GPT-2 reaguje na sledeći upit: “Pitanje: Koji je glavni grad Francuske? Odgovor: Pariz Pitanje: Koji je glavni grad Poljske? Odgovor:”
Tim je proučavao verziju GPT-2 sa 24 sloja. Nakon svakog sloja, naučnici su ispitivali model kako bi posmatrali njegovo najbolje predviđanje sledećeg tokena. Tokom prvih 15 slojeva, najbolje predviđanje je bila naizgled nasumična reč. Između 16. i 19. sloja, model je počeo da predviđa da će sledeća reč biti Poljska - nije ono što očekujemo ali ide u dobrom pravcu. Zatim se u 20. sloju predviđanje promenilo u Varšava - tačan odgovor - i ostalo je tako u poslednja četiri sloja.
Istraživači su otkrili da je 20. feed-forward sloj pretvorio Poljsku u Varšavu dodavanjem vektora koji mapira vektore država u njihove odgovarajuće glavne gradove. Dodavanje istog vektora Kini proizvelo je Peking.
Feed-forward slojevi u istom modelu koristili su vektorsku aritmetiku za transformaciju reči iz malih u velika slova i reči iz sadašnjeg u prošlo vreme.
Slojevi pažnje i feed-forward slojevi imaju različite zadatke Link to heading
Do sada smo pogledali primer predviđanja reči GPT-2 iz stvarnog sveta: glave pažnje koje pomažu u predviđanju da je Milan dao auto na popravku i feed-forward sloj koji pomaže u predviđanju da je Varšava glavni grad Poljske.
U prvom slučaju, “Milanov” je došla iz upita koji je dao korisnik. Ali u drugom slučaju, “Varšava” nije bila u upitu. GPT-2 je morao da “zapamti” činjenicu da je Varšava glavni grad Poljske - informaciju koju je naučio iz podataka za treniranje.
Kada su istraživači sa Brauna isključili feed-forward sloj koji je pretvorio Poljsku u Varšavu, model više nije predviđao Varšavu kao sledeću reč. Međutim, zanimljivo je da ako su zatim dodali rečenicu “Glavni grad Poljske je Varšava” na početak upita, GPT-2 je ponovo mogao da odgovori na pitanje. Ovo je verovatno zato što je GPT-2 koristio glave pažnje da kopira ime Varšava iz ranijeg dela upita.
Ova podela posla važi i šire: Glave pažnje preuzimaju informacije iz ranijih reči u upitu, dok feed-forward slojevi omogućavaju jezičkim modelima da “zapamte” informacije koje nisu u upitu.
Same feed-forward slojeve možemo da gledamo kao na baze podataka informacija koje je model naučio tokom treniranja iz samih podataka. Raniji feed-forward slojevi češće kodiraju jednostavne činjenice vezane za specifične reči, kao npr. “Trump često dolazi posle reči Donald”. Kasniji slojevi kodiraju složenije odnose poput “dodaj ovaj vektor da pretvoriš državu u njen glavni grad”.
Zaključak Link to heading
Kroz detaljnu analizu rada LLM-ova, možemo izdvojiti pet ključnih komponenti koje omogućavaju njihovo funkcionisanje:
-
Transformeri i slojevi
- Moderni LLM-ovi koriste višestruke transformacijske slojeve (32-126+)
- Rani slojevi fokusiraju se na sintaksu i osnovne veze
- Kasniji slojevi razumeju složenije kontekste i značenja
- Svaki sloj doprinosi boljem razumevanju teksta
-
Mehanizam pažnje
- Omogućava razmenu informacija između reči kroz query-vektor i key-vektor
- Koristi više glava pažnje za paralelnu obradu različitih aspekata teksta
- Rešava probleme kao što su reference zamenica i višeznačnost reči
-
Feed-forward mreže
- Analiziraju pojedinačne reči sa svim prikupljenim kontekstom
- Prepoznaju specifične obrasce u tekstu
- Obrasci postaju sve apstraktniji kroz dublje slojeve
-
Dvostruki mehanizam obrade
- Glave pažnje: Obrađuju informacije iz trenutnog konteksta
- Feed-forward slojevi: Služe kao “baza znanja” naučena tokom treniranja
- Zajedno omogućavaju kombinovanje kontekstualnih i memorisanih informacija
-
Vektorska matematika
- Reči su predstavljene kao vektori sa 4096 dimenzija
- Omogućava složene operacije poput mapiranja država u glavne gradove
- Podržava analogno zaključivanje (npr. Berlin = Nemačka + Francuska = Pariz)
- Dozvoljava precizno čuvanje konteksta i značenja
Ova složena arhitektura omogućava LLM-ovima da kombinuju trenutni kontekst sa prethodno naučenim znanjem, rezultirajući impresivnom sposobnošću razumevanja i generisanja teksta. Iako još uvek ne razumemo u potpunosti sve detalje njihovog funkcionisanja, jasno je da kombinacija velikog broja parametara, višestrukih slojeva obrade i sofisticiranih mehanizama za obradu konteksta omogućava izuzetne rezultate u obradi prirodnog jezika.